Building a Vision Transformer from Scratch in PyTorch
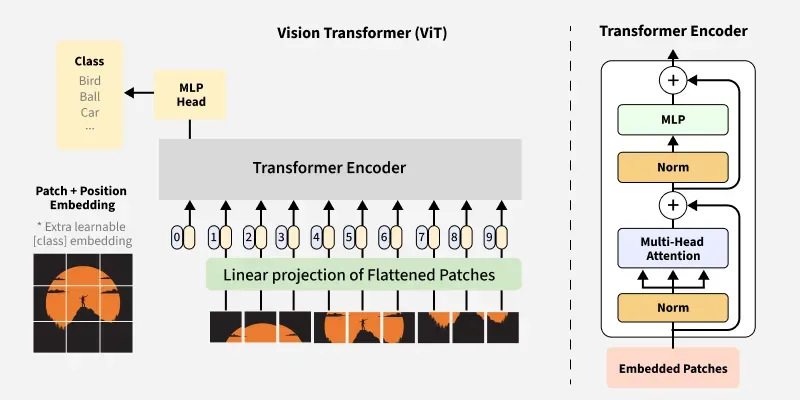
Step-by-step implementation of ViT - patch embeddings, positional encodings, and the classification head - trained on CIFAR-10 with a detailed ablation study.

Artificial Intelligence › Deep Learning
Explore neural networks, transformers, large language models, computer vision, generative AI, diffusion models, reinforcement learning, and the latest breakthroughs shaping the future of Artificial Intelligence research.
Review Article Open Access
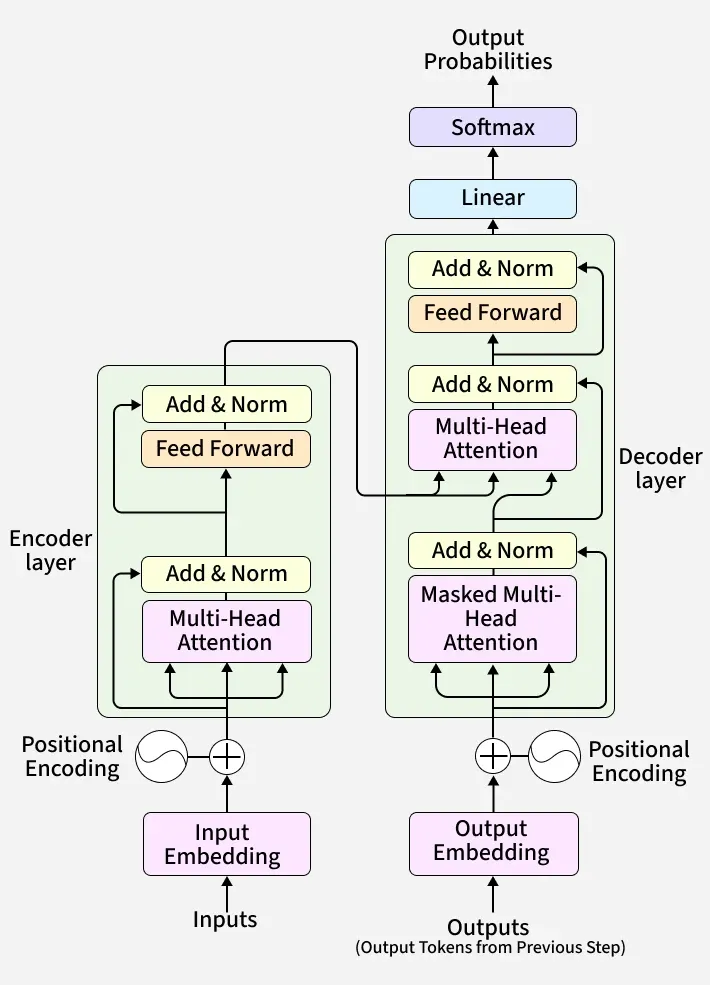
Self-attention, positional embeddings, and multi-head attention - a ground-up walkthrough of how transformer networks power ChatGPT, Gemini, Claude, and every major large language model in production today. We cover architecture variants, scaling laws, and what comes next.
Step-by-step implementation of ViT - patch embeddings, positional encodings, and the classification head - trained on CIFAR-10 with a detailed ablation study.
An analysis of compute-optimal training, Chinchilla's findings, and how model size and data volume interact - with implications for the next generation of frontier models.

How denoising diffusion probabilistic models work, why they outperform GANs on image generation, and a walkthrough of the latent diffusion architecture behind Stable Diffusion.

Explainer
The mechanism that made NLP fast and scalable - explained with diagrams, no math required.
12 Jun 2026 · 6 min read
Tutorial
Practical walkthrough of parameter-efficient fine-tuning - runs on a single consumer GPU.
10 Jun 2026 · 10 min read
Research
An honest look at SSMs, their O(n) compute advantage, and where they still fall short.
8 Jun 2026 · 13 min read
Guide
MLflow, Weights & Biases, and containerised serving - a complete production checklist.
6 Jun 2026 · 8 min read
Deep learning is a subfield of machine learning that uses multi-layered artificial neural networks to learn representations directly from raw data - images, text, audio, and beyond. Unlike traditional ML pipelines that depend on hand-crafted features, deep networks learn hierarchical features automatically, making them extraordinarily powerful for perception tasks.
The transformer architecture, introduced in Attention Is All You Need (Vaswani et al., 2017), replaced recurrent networks as the dominant paradigm in NLP. Today, GPT-4, Gemini, Claude, and Llama 3 are all built on transformer variants. Research on scaling laws (Hoffmann et al., 2022) showed that both data and model size must grow together for efficient training - a finding that reshaped how frontier labs budget compute.
Diffusion models - DALL·E 3, Stable Diffusion, Midjourney - have supplanted GANs for image synthesis. Their training stability and sample diversity make them the go-to choice for multimodal generation. Recent work extends diffusion to video (Sora), audio, and protein structure prediction.
RLHF and its variants (DPO, ORPO) are the techniques behind the alignment of large language models. Combining supervised fine-tuning with a reward model trained on human preferences produces the conversational assistants widely used today.